
Multi-repo projects deserve multi-repo memory
Most software that ships to users is not one repo. A mobile app has a backend service, a shared SDK, maybe a design system package. A platform might have a core engine in one language and a web dashboard in another. Each piece lives in its own repository with its own build system, its own tests, its own history.
This is a good architecture. But it creates a coordination gap. When you use an AI coding agent in one repo, it has full context for that repo: tickets, issues, handovers, lessons learned. It knows nothing about the other repos in the system. It cannot see that a ticket it is about to recommend depends on unfinished work in a sibling repo. It cannot tell you that three modules are blocked on the same bottleneck.
Storybloq 1.4 introduces federation: a way for one project to declare the relationships between repos and read across all of them. This post explains why multi-repo architecture matters, how federation works, and what it looks like in practice.
01 / Why multi-repo
A monorepo puts everything in one place. That works until it does not. When your project has a Swift engine, a TypeScript cloud backend, a React Native mobile client, and a shared component library, putting them in one repo means one CI pipeline trying to build four different toolchains. A failing linter in the cloud code blocks a release of the engine. A dependency update in the mobile client triggers a full rebuild of everything.
Splitting into separate repos gives each module its own build, its own test suite, its own release cycle. The engine runs 1,800 tests in Swift. The cloud backend runs 272 tests in TypeScript. Neither knows about the other's toolchain. A bug in the cloud API does not break the engine's CI. A new version of the engine can ship without waiting for the mobile client to catch up.
Separate repos also mean parallel development. Two engineers can build two modules at the same time without stepping on each other. No merge conflicts over shared files. No waiting for someone else's PR to land before you can start. Each module moves at its own pace.
This compounds with AI coding agents. Each module can have its own agent session running Storybloq's autonomous mode: planning, implementing, testing, reviewing, and committing independently. One agent builds the engine's audio pipeline while another scaffolds the cloud API. A third sets up the component library. They do not compete for the same files, the same branch, or the same CI queue. Each agent has a focused context: just the code, tests, and history relevant to its module.
The tradeoff is coordination. In a monorepo, dependencies are implicit: everything is right there. In a multi-repo setup, the relationships between modules need to be declared somewhere. The app shell depends on the engine. The cloud backend consumes the client SDK. The UI components call into a bridge layer that connects them. These dependencies are real, but without tooling they live in developers' heads. "Don't start the app shell until the conductor is done" is tribal knowledge that evaporates between sessions.
The value of multi-repo is independence: each module can be built, tested, and released on its own terms. The cost is coordination: someone or something needs to know how the pieces connect. Federation makes those connections explicit and machine-readable.
02 / What federation looks like
One project becomes the orchestrator. It declares which repos are part of the system, how they depend on each other, and how they communicate at runtime. Each repo keeps its own .story/ directory with its own tickets, issues, and handovers. The orchestrator reads across all of them.
A node entry in the orchestrator's config looks like this: a name, a path to the repo, a stack identifier, an optional role description, and a dependsOn array naming other nodes that must be built first. Runtime integration links (API calls, shared protocols) are declared separately from build-time dependencies.
Tickets can declare cross-node blocking: crossNodeBlockedBy: ["engine:T-042"]. This tells the recommendation engine that this ticket cannot proceed until ticket T-042 in the engine repo is complete. The blocking is checked live against the actual ticket status in the other repo.
Setting it up takes two commands:
storybloq init --type orchestratorstorybloq node add engine --path ../engine --stack swift-spm --role "Core engine"
Repeat node add for each module. The CLI validates paths, checks for cycles in dependsOn, and prevents self-references. If you have previously used a wrapper repo with a single shared .story/ above nested repos, federation is different: each node keeps its own project memory. The orchestrator declares the edges and reads across them. The wrapper pattern works for co-located monorepos. Federation is for truly separate repos.
03 / What the orchestrator sees
storybloq status from the orchestrator directory aggregates across all nodes. In our test project, that means one view showing 8 nodes, 465/521 tickets complete, and 122 open issues.
storybloq recommend generates federation-specific suggestions. A red node blocking 3 downstream modules surfaces first. A node with no handover in two weeks gets flagged. A bottleneck node depended on by multiple others but only 40% complete shows up early so you can prioritize it.
Cross-node blocking is where this becomes most useful. A ticket in the app shell with crossNodeBlockedBy: ["conductor:T-015"] will not appear in recommendations until that conductor ticket is marked complete. This prevents an agent from starting work that depends on code that does not exist yet in another repo.
The --node flag lets you operate on any module from the orchestrator directory. storybloq ticket list --node engine shows the engine's tickets without changing directories. Agents can create tickets, update status, and read state across any node without leaving the orchestrator context.
During development, the recommendation engine surfaced that the conductor node, depended on by 3 other modules, had zero complete tickets. It was the first recommendation, before any module tried to integrate with it.
04 / Seeing the graph
The Mac app's 1.1.0 update adds visual federation support. When you open an orchestrator project, three new views are available.
The Nodes tab shows a dependency graph: nodes rendered as cards, arranged in topological layers, connected by edges. Build-time dependencies are solid lines. Runtime integration links are dashed. Select a node and unrelated nodes dim, letting you trace one module's dependency chain.
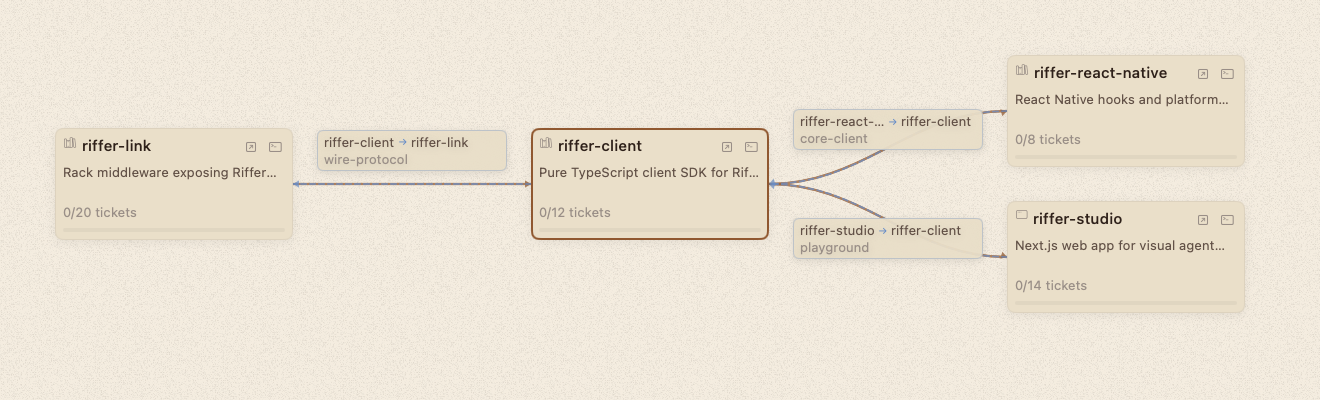
In the Board view, a compact mini graph sits at the top of the kanban. Each node is a pill showing its name and progress. You can see at a glance which modules are complete and which are behind. Click the expand button to jump to the full Nodes view.
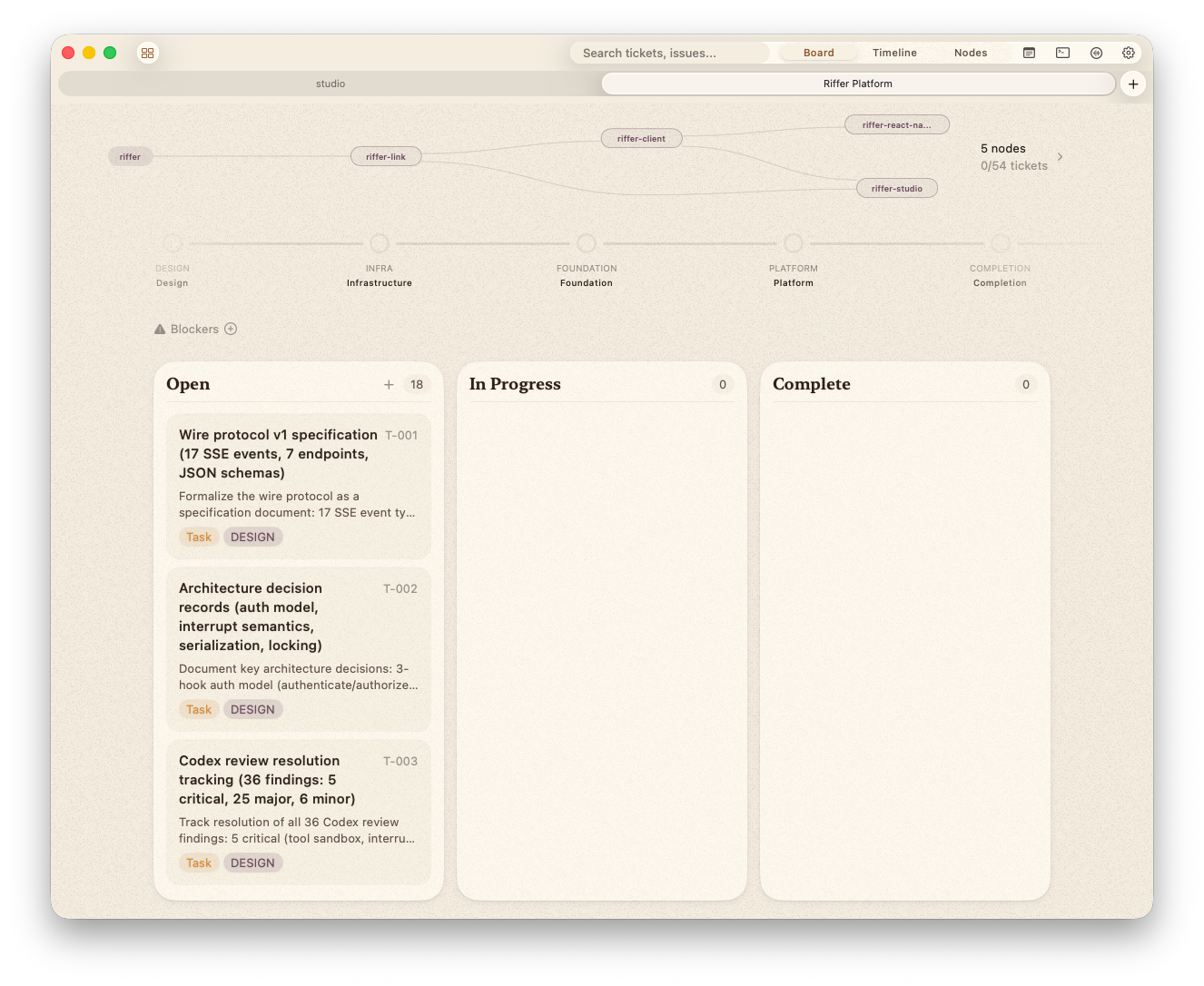
Select a node in the graph and an inspector sidebar opens. It shows live ticket preview (pulled from the node's repo via security-scoped bookmarks), build-order dependencies, runtime links, and the last handover summary. The CLI gives agents the coordination primitives. The Mac app gives humans the graph. Both read the same .story/ files.
05 / Why files, not a service
Federation state lives in two files. config.json holds the node map and dependency edges. It is git-tracked, so changes to the federation graph show up in diffs and pull requests like any other code change. federation-cache.json holds scanned ticket counts and health data. It is gitignored and regenerated automatically when the cache expires.
Every node is a complete, independent storybloq project. Remove it from the orchestrator's config and it still works on its own. Add it back and the orchestrator picks it up again on the next scan.
Because federation is just files and CLI commands, AI agents can set it up too. In testing, a Claude Code agent configured an 8-node orchestrator from a description of the system architecture, using storybloq init --type orchestrator and then node add for each module with dependency edges and runtime links. The structured commands meant it never had to edit config.json directly.
In our previous post we argued that the repository is the right substrate for AI engineering memory. Federation extends that argument: if the repo is the right place for single-project memory, it is the right place for multi-project coordination too.
06 / Limits
Federation requires discipline. If nobody maintains the dependency edges and cross-node blockers, the graph rots. The tooling helps: cycle detection blocks invalid writes, referential integrity checks catch dangling node references. But the human has to want the structure.
Federation is local only. The orchestrator reads node directories from the filesystem. All repos must be on the same machine. Remote federation (clone on demand, CI integration) is not built yet.
Node health (green, yellow, red, grey) is set manually, not derived from scan results. The agent or the developer sets it based on context the scanner cannot infer: a node might be red because a vendor API key is pending, not because the code is broken.
The arc so far: single-session memory, then cross-session continuity, now multi-repo coordination. The same project management primitives that work for a single repo (tickets, issues, phases, handovers) extend naturally across the federation. Each step made the next one possible.